Value-based Token Pricing
I find two commonly used pricing plans for token consumers:
Price per Token
Sometimes you can “pay as you go.” That means you are charged based on the exact number of consumed tokens and the token types (e.g., output tokens are more expensive; cached prefix tokens are cheaper). This is common when calling LLMs through model APIs and often allows for high request concurrency based on the user tier.
Concerns:
- Users don’t want surprising bills as they can be billed unlimitedly without careful budget configuration.
- You are paying for whatever an LLM generates, even if they generate buggy code or hallucinated content.
- What if some labs intentionally optimize models for longer generation just to inflate token counts for more profits?
Subscription
Subscription-based pricing charges a fixed monthly fee for a given plan (e.g., Cursor Pro/Ultra, Claude Pro/Max). A more expensive plan often (i) allows for a higher usage limit or priority and (ii) unlocks more features. This is a common practice for LLM-driven applications such as chat bots, coding agents, etc.
The subscription-based approach nudges users to consume more tokens:
- If you just use the product occasionally, you are overpaying.
- But if you use the app fairly frequently, you actually get more value than you pay for, e.g., people can consume monthly tokens that can cost thousands or even tens of thousands of dollars at pay-per-token rates.
Concerns:
- Even the “max” plan can be limited. Overuse gets you frequent blocks, slower requests, and even quality degradation.
- Is it a fair deal for the model provider? Probably yes if they really want people to use it more. Probably no if everyone uses a lot more tokens than what their plans pay for.
I’ve been imagining a new pricing strategy called “price per value.”
Price per Value
Ideally, user-side cost should be co-determined by the value it creates to the user and the serving-side cost. A simple model could be:
\[{\rm \bf Price}(x,y) = {\rm \bf Value}(y)\times {\rm \bf Cost}(x;y)\]Let’s exemplify under the coding scenario. We can estimate “Value(y)” as:
- 1 (or bigger) if the user accepts the agent-suggested patch
- 0 or some small base factor (say 0.1) when rejected
This billing model has two good implications:
- The user cost is highly correlated to the value that the LLM product offers
- Incentivizes labs to build better models and products that suit user needs
When does it make sense? Say for coding, sometimes I don’t code much so the cost should be (near-)zero, while when working on some projects I can run many long-horizon coding tasks and do not want to be bothered by annoying user limits or overspending on broken results models occasionally produce.
Concerns:
- It still inherits “surprise bills” and “thinking inflation” from price per token.
- It needs a reasonable value function, which is unavailable in scenarios that cannot collect genuine user feedback. For example, coding products can track user acceptance; however, there’s no reliable user feedback in chatbots as people may thumbs-down responses that actually worked. More importantly, the feedback should be in the flow: e.g., in coding, accepting/rejecting LLM-generated patches is a critical path, but in chatbots giving thumbs up and down requires additional steps that could annoy users.
Summing up
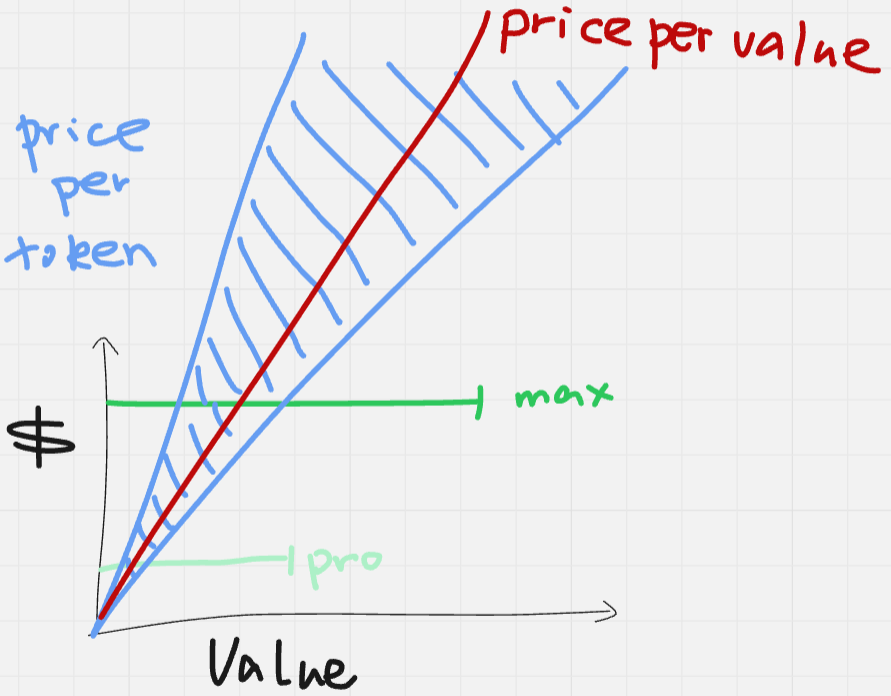
We can draw a figure where the x-axis is the value a product produces and the y-axis is the user-side cost.
- Subscription-based pricing offers fixed cost and capped value, which is best for personal usages that just hit the limit, but bad for both extreme under- and over-usages.
- Price per token has big variance and is best for high-volume, stable production usages, but bad for blind usages that could cause a surprise bill.
- Price per value is reasonable and balanced for most scenarios and incentivizes labs to build really useful models. However, it requires implementing the value function, which is either unavailable or hackable.